先端技術の開発と活用
AIの活用
AIを活用することは、多くの分野で革新的な成果をもたらしています。AIは機械学習や数学的アルゴリズムやパターン認識に基づいて学習し、大量のデータを高速かつ精度の高い予測に変換します。
AIの活用事例として、「例1:トンネル湧水量の予測」「例2:地震時における最大層間変形角の推定」を紹介します。
例1:トンネル湧水量の予測
トンネル掘削において、突発湧水などの状況に備えて湧水量の計測を行っています。その湧水量からその近傍の透水係数を予測することができれば、その後の予測解析の精度向上が期待できます。そこで、日単位で計測した切羽湧水量から、前方の透水係数を推定するAIモデルの構築を行います。
教師データの作成
ここでは、図1に示すような単純な地盤・トンネルモデルを用いて、地下水流れのシミュレーションを実施し教師データの作成を行います。
このとき、表1に示すとおり、入力条件となる「透水係数」、「掘進距離」,「トンネル径」,「降雨量」,「土被り(初期地下水位)」の値を一定の幅で変更し、多数の解析を行います。最終的な教師データとしては、約2億パターンを準備しました。このデータを準備するのに、複数のPCでバッチ処理を行い数週間費やしました。これらの解析では、各条件に対応した出力として「水位」、「湧水量」などを得ることができます。
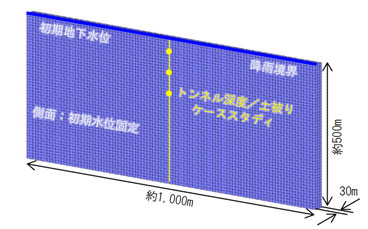
表 1 解析パターン

この解析で得られた入力条件と出力の関係をAIに学習させ、出力から入力条件を推定できるようにします。この結果、出力である湧水量に計測値を適用することで、入力条件である透水係数を推定できるようなります。
GBDTによる学習
AIによる透水係数の同定のための学習を行うにあたって、勾配ブースティング決定木(Gradient Boosting Decision Tree、以下GBDT)を採用しました(図3)。GBDTでは、条件分岐によって問題を解く「決定木」を用いて回帰あるいは分類問題を解き、誤差の大きい決定木の損失関数の値が小さくなるように新たな決定木を構築し、モデルを改善していきます。本手法は、「ブースティング」を用いたアンサンブル学習の一つに位置づけられます。
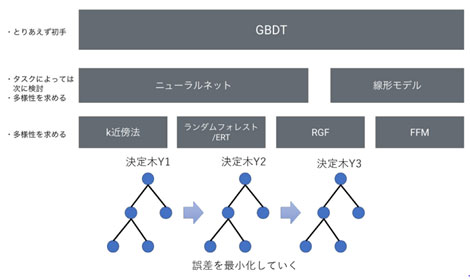
(引用元:門脇大輔、阪田隆司、保坂桂祐、平松雄司(2019)「Kaggleで勝つデータ分析の技術」技術評論社,p.230より、決定木の図を当社で追加)
ニューラルネットワークによる学習
本手法では、期待する精度には至らなかったため、表1にあるように教師データの量を可能な限り追加して、AIのアルゴリズムもニューラルネットワークに変更して解析を行うことにしました。ニューラルネットワークのアーキテクチャーを図4に示します。ここでは、単純な4層構造のネットワークを用いています。
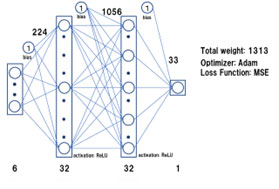
学習の方法としては、すべてのパラメータを一括で学習する(バッチ学習)のではなく、少量のバッチに分けて学習し、重みを最適化していく手法(ミニバッチ学習)を採用しています、具体的には、行数で32行(バッチ)をひとまとまりとして、2500×1834回繰り返し計算を行う、重みを修正していきます。ここで、32行なのは、DNNのネットワークが今回使用したGPUの上限8GBに相当しています。計算時間としては、約5時間程度で、繰り返して計算することで局所最適解を補正して、確率的最適解を計算することができます。
予測結果と実測値の比較
最終的に、AIモデルによって推定された透水係数を実現場のモデルに反映して予測解析を行い、得られた湧水量の予測結果を図5に示します。再現解析における日湧水量の結果はある程度値はばらついているものの、整合性は高いことがわかります。
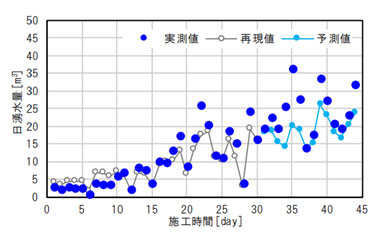
現場で取得可能な物理量である湧水量から、透水係数を求めるAIモデルの構築において、地下水流れの解析を教師データとして使用した例を示しました。この教師データの作成自体は、用いるパラメータの幅や分割などを予め決定しておけば、バッチを用いて一気に解析し、収集することが可能です。
例2:地震時における最大層間変形角の推定
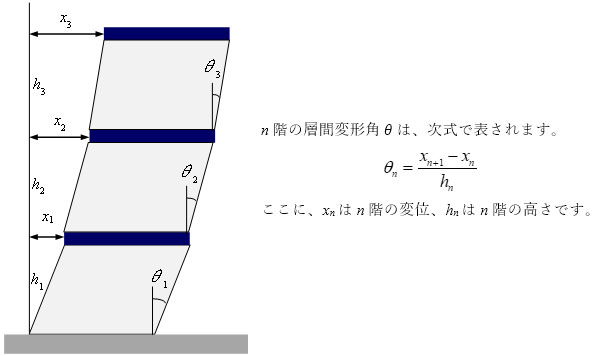
地震時における建物の損傷を評価する重要な指標の一つに、層間変形角(図1)があります。層間変形角が大きくなると構造の耐力が奪われ、建物の倒壊を引き起こす場合があります。
地震時の層間変形角を求めるためには、加速度センサなどで建物の地震時の振動を計測することが必要ですが、計測装置が設置された建物の地震時のデータをAIに学習させ、計測装置がない場合でも層間変形角が推定する方法を検討します。
層間変形角とは?
図1に層間変形角の定義を示します。水平方向の振動によって発生する建物のせん断ひずみに相当します。
教師データの作成
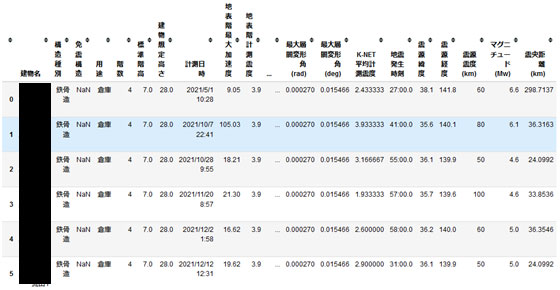
地震時の建物における最大層間変形角を推定するために、これまで収集された地震時に建物で計測された振動データ(震度、加速度、層間変形角など)や、震源情報(マグニチュード、震源距離など)に加え、建物の構造(階数、階高、工法など)を説明変数として、最大層間変形角を目的変数とするAIモデルの構築を行います。
表1 地震と建物の情報
機械学習のアルゴリズム
使用する手法は、教師あり学習の1種であるXGBoost、CatBoost、LightGBMの3つを用います。これらは、いずれも勾配ブースティングに基づく機械学習アルゴリズムで、以下のような特徴があります。
- XGBoost:高度に最適化された勾配ブースティングライブラリで、並列化された訓練プロセス、L1(Lasso)とL2(Ridge)の正則化、欠損値の自動処理とツリーのプルーニングなどが特徴です。これらの特性により、XGBoostはスケーラビリティ、モデルの性能、効率に優れています。
- LightGBM:大量のデータと高次元の特徴を扱うために設計された勾配ブースティングライブラリです。勾配に基づく片面サンプリング(GOSS)と排他的機能バンドル(EFB)により、計算とメモリの効率を向上させています。また、リーフワイズを採用しており、精度が高いモデルを生成します。
- CatBoost:ロシアの検索エンジンで有名なYandex社により開発された勾配ブースティングライブラリで、特にカテゴリカル変数の処理に優れています。カテゴリ変数の自動エンコーディング、過学習を防ぐためのOrdered Boosting、そしてGPUを活用した訓練の高速化が可能な点が特徴です。
全てのデータを機械学習に用いると、作成されたモデルの精度を評価することができません。したがって、任意の割合で教師データと検証データに分割します(ホールドアウト検証:Holdout Method)。ここでは、その比率を9:1としています。
層間変形角と他の因子との相関性
図2~図4に用いたデータにおけるAIモデルの精度を示します。左のグラフは、評価データ(Out of Fold)と予測データ(Test Predict)のヒストグラム示し、右のグラフは、評価データ(Observed)と予測データ(Predicted)の相関図を示しています。また、表2にそれぞれのモデルの性能指標値を示します。
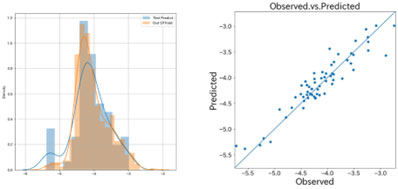
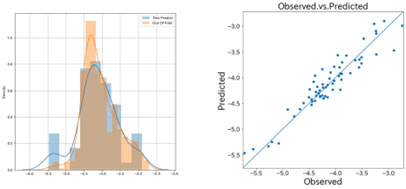
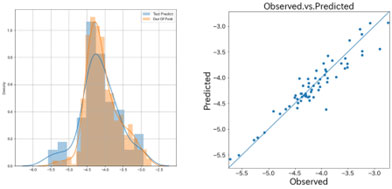
表2 モデルの性能指標値
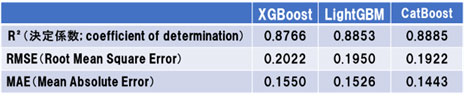
決定係数で見る限り、どのモデルにおいても85%を超えており、それなりの性能が出ていることがわかります。今回は、特徴量は、提示されたもののみを使用しているため、もっと効果のある特徴量を作成することができれば、さらに性能を上げることができます。
また、これらからは特徴量重要度(Feature Importance)を計算することができます。図5は、LightGBMにおける計算で求まった特徴量重要度を示しています。
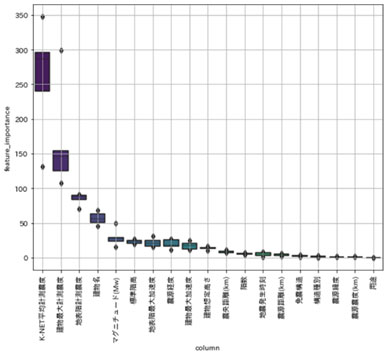
これにより、どの特徴量が最大層間変形角に寄与するのかがわかります。また、寄与しない特徴量を削除することも可能になります。