技術資料
Feel&Think
第13回 強化学習(その3)
前回の「強化学習(その2)」では、強化学習についてその基礎となる「マルコフ決定過程」、「ベルマン方程式」、「動的計画法」、「モンテカルロ法」について解説しました。
今回は、引き続き強化学習において基礎となる「TD法」、「ニューラルネットワークとQ学習」、「方策勾配法」について説明していきます。
TD法
■TD法って何?
TD法(時間差分法、Temporal Difference Learning)は、強化学習の一種で、未来の報酬を考慮しながら現在の価値を学習する方法です。TD法は、モンテカルロ法と動的計画法の両方の特徴を持ち、効率的に価値を更新することができます。
■どんなときに使うの?
TD法は、ゲームの戦略学習やロボットの動作計画、金融市場の予測など、さまざまな分野で使われます。例えば、チェスや将棋のような複雑なゲームの戦略を学習するのに役立ちます。
■TD法の基本概念
価値関数の更新
TD法では、現在の価値関数を次のように更新します:
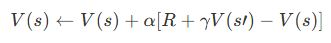
ここで、
- V(s):状態 s の価値
- α:学習率(0<α≦1)
- R:即時報酬
- γ:割引率(0≦γ<1)
- s’:次の状態
TD誤差(TD Error)
TD誤差は、予測と実際の差を示します。TD誤差を使って価値関数を更新します。
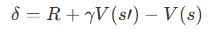
価値関数と行動価値関数
TD法は、状態の価値(状態価値関数)だけでなく、特定の行動の価値(行動価値関数)も学習できます。
- 状態価値関数 V(s):状態sの価値
- 行動価値関数 Q(s,a):状態sで行動aを取ったときの価値
■TDの具体例
TD(0)アルゴリズム
TD(0)は、最も基本的なTD法のアルゴリズムです。一歩先の未来の報酬を使って価値を更新します。
問題設定
- ある迷路で最短経路を学習する
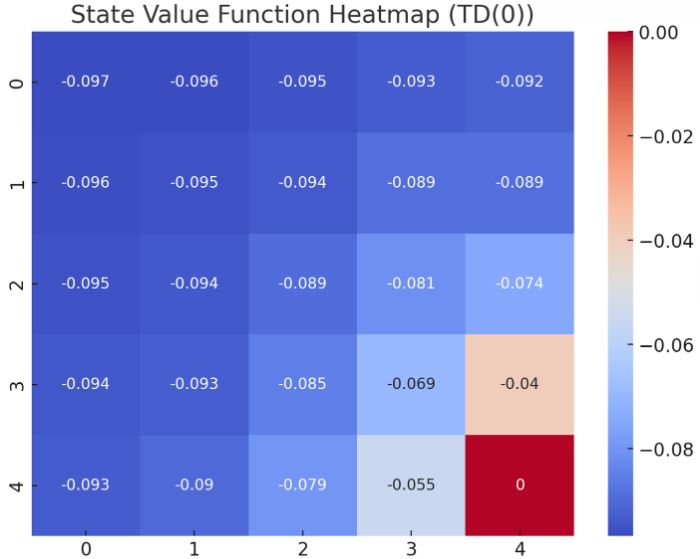
最終状態(4,4)に近づくほど価値が高くなっていることが確認できます。この結果は、エージェントが最終状態に到達するための経路に沿って価値が徐々に高まることを示しています。最終状態は報酬を得られるため、価値は0(または1)であり、それ以外の状態は負の報酬が適用されるため、マイナスの値となっています。
SARSAアルゴリズム
SARSAは、TD法の一種で、行動価値関数Q(s,a)を学習します。次の行動を実際に選んだ行動に基づいて更新します。
問題設定
- ある迷路で最短経路を学習する
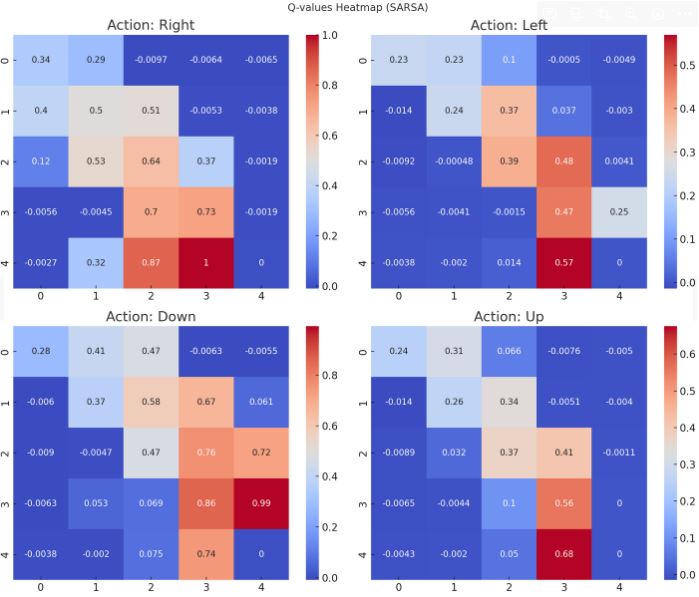
このSARSAアルゴリズムの実行結果として、迷路内の各状態での4つの行動(上、下、左、右)に対するQ値が計算されました。Q値は、エージェントがゴールに向かって効率的に移動するように学習したことを示しています。
■TD法の応用
ゲームの戦略学習
TD法は、チェスや将棋などの戦略ゲームで最適な戦略を学習するために使われます。AIがゲームをプレイしながら、自分の価値関数を更新していきます。
ロボット制御
ロボットの動作計画にもTD法が使われます。ロボットが環境と相互作用しながら、最適な動作を学習します。例えば、障害物を避けながら目的地に向かう方法を学習します。
金融市場の予測
TD法は、金融市場の予測やトレーディングアルゴリズムにも応用されます。市場データを使って、将来の価格変動を予測し、最適な売買戦略を学習します。
■TD法の実践
アルゴリズムの設計
TD法を実践する際には、以下のステップを踏みます:
- 問題の定義と目標の設定
- 状態と行動の定義
- TD誤差を計算して価値関数を更新
- 学習率と割引率の調整
効率的な実装
効率的な実装のためには、計算時間とメモリ使用量を考慮することが重要です。また、学習率と割引率を適切に設定することで、学習の効率を高めることができます。
ニューラルネットワークとQ学習
■ニューラルネットワークって何?
ニューラルネットワークは、人間の脳を模倣した計算モデルです。多層の「ニューロン」が互いに接続され、データを入力して処理し、出力を生成します。これにより、画像認識や音声認識などの複雑なタスクを解決できます。
■Q学習って何?
Q学習は、強化学習の一種で、エージェントが環境と相互作用しながら最適な行動を学習する方法です。エージェントは、行動を取るたびに得られる報酬を基に、「Q値」と呼ばれる価値を更新し、次に取るべき最適な行動を選びます。
■Q学習の基本概念
Q値と行動価値関数
Q値(Q-value)は、状態 s で行動 a を取ったときに期待される累積報酬のことです。行動価値関数 Q(s,a) は、各状態・行動ペアに対するQ値を示します。
(例:迷路での位置(状態)と進む方向(行動)に対するQ値)
Q学習アルゴリズム
Q学習では、次のようにQ値を更新します:
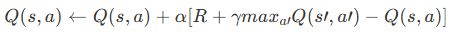
ここで、
- α:学習率
- γ:割引率
- R:即時報酬
- s’:次の状態
- a’:次の行動
ε-グリーディー法
ε-グリーディー法は、探索と活用のバランスを取るための方法です。εの確率でランダムな行動を取り、1-εの確率で最適な行動を取ります。
例:ε=0.1なら、10%の確率でランダムな行動、90%の確率で最適な行動を選びます。
■ニューラルネットワークとQ学習の融合
Deep Q-Network(DQN)
ニューラルネットワークとQ学習を組み合わせたものが、Deep Q-Network(DQN)です。DQNは、ニューラルネットワークを使ってQ値を近似し、より複雑な問題を解決することができます。DQNは、DeepMind社によって開発され、アタリゲームなどで人間以上のパフォーマンスを発揮することで知られています。
例:ゲームのプレイングAIで、画面のピクセル情報を入力として最適な行動を出力する。
経験リプレイ
DQNでは、経験リプレイと呼ばれる技術を使います。エージェントが環境と相互作用した経験をメモリに保存し、ランダムにサンプリングして学習します。これにより、データの相関を減らし、学習の安定性を高めます。
例:ゲームのプレイデータを保存し、後でランダムに取り出して学習する。
ターゲットネットワーク
DQNでは、ターゲットネットワークを使ってQ値の更新を安定化します。一定の間隔で、ターゲットネットワークのパラメータを現在のネットワークのパラメータで更新します。
例:100ステップごとにターゲットネットワークを更新する。
■ニューラルネットワークとQ学習の具体例
問題設定
・ある迷路で最短経路を学習する
アタリゲームのDQN解法
DQNは、アタリゲームのような複雑な環境でも使われます。画面のピクセル情報を入力として、最適な行動を出力するニューラルネットワークを学習します。
方策勾配法
■方策勾配法って何
方策勾配法は、強化学習における手法の一つで、エージェントが直接方策(policy)を学習します。方策とは、状態に基づいて行動を選択するルールのことです。方策勾配法では、方策をパラメータ化し、報酬を最大化するためにそのパラメータを最適化します。
■どんなときに使うの?
方策勾配法は、連続的な行動空間や大規模な状態空間を持つ問題に適しています。例えば、ロボットの動作計画やゲームの戦略学習に使われます。
■方策勾配法の基本概念
方策(Policy)
方策 π(α∣s;θ)は、状態 s に基づいて行動 a を選択する確率分布です。ここで、 θ は方策のパラメータです。
例:ロボットが特定の状態で進む方向を選ぶ確率
方策のパラメータ化
方策をパラメータ θ で表現し、そのパラメータを学習します。ニューラルネットワークを使って方策を近似することが一般的です。
例:ニューラルネットワークの重みθを学習して最適な方策を見つけるθ
目的関数と報酬
方策勾配法の目的は、累積報酬を最大化することです。目的関数 J(θ)は、エージェントが得る期待報酬を示します。
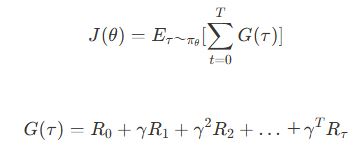
ここで、
- γ:割引率(0<=γ<1)
- Rt:時刻 t での報酬 t
■方策勾配法の具体的な手法
REINFORCEアルゴリズム
REINFORCEは、基本的な方策勾配法の一つです。方策のパラメータを報酬に基づいて更新します。
アルゴリズムのステップ
- エピソードをサンプル
- 各ステップでの報酬を記録
- 方策のパラメータを更新
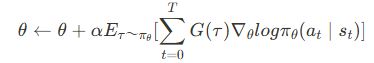
ここで、
- α:学習率
■Pythonでの実装例
Actor-Criticアルゴリズム
Actor-Criticは、方策勾配法と価値関数を組み合わせた手法です。Actorは方策を学習し、Criticは価値関数を学習します。
アルゴリズムのステップ
- エピソードをサンプル
- Criticが状態の価値を評価
- Actorが方策を更新
■方策勾配法の応用
ロボット制御
方策勾配法は、ロボットの動作計画にも使われます。例えば、ロボットが障害物を避けながら目的地に向かう方法を学習します。
ゲームの戦略学習
方策勾配法は、チェスや将棋などの戦略ゲームで最適な戦略を学習するために使われます。AIがゲームをプレイしながら、自分の方策を更新していきます。
自動運転
自動運転車の制御アルゴリズムにも方策勾配法が応用されます。車が道路状況をカメラで観察し、最適な運転行動を決定します。
■方策勾配法の実践
アルゴリズムの設計
方策勾配法を実践する際には、以下のステップを踏みます:
- 問題の定義と目標の設定
- 方策ネットワークの設計と構築
- 価値関数の定義と学習
- 方策のパラメータを更新
効果的な実装
効率的な実装のためには、計算時間とメモリ使用量を考慮することが重要です。また、学習率と割引率を適切に設定することで、学習の効率を高めることができます。GPUを利用することで、大規模なニューラルネットワークのトレーニングも可能になります。
まとめ
TD法(時間差分法、Temporal Difference Learning)は、未来の報酬を考慮しながら現在の価値を学習するための強力なツールです。ゲームの戦略学習やロボットの動作計画、金融市場の予測など、さまざまな分野で応用されています。TD法を理解し、実践することで、複雑な問題を効率的に解決する力を身につけることができます。
ニューラルネットワークとQ学習は、それぞれ強力な機械学習技術ですが、これらを組み合わせることでさらに強力な手法になります。Deep Q-Network(DQN)は、その一例であり、複雑な問題を解決するための効果的なツールです。ニューラルネットワークとQ学習を理解し、実践することで、ゲームの戦略やロボットの動作計画など、さまざまな応用が可能になります。
方策勾配法(Policy Gradient Methods)は、強化学習における重要な手法であり、エージェントが直接方策を学習するために使われます。連続的な行動空間や大規模な状態空間を持つ問題に適しており、ロボット制御やゲームの戦略学習、自動運転など、さまざまな分野で応用されています。方策勾配法を理解し、実践することで、複雑な問題を効率的に解決する力を身につけることができます。
今回は、強化学習についてその基礎となる「TD法」、「ニューラルネットワークとQ学習」、「方策勾配法」について説明しました。次回は、「超解像(Super Resolution, SR)」技術について詳しく紹介していきます。